

Storage Layer Maximalism
Storage layer maximalism and why every NFT needs an IPFS CID.
Storage Layer Maximalism
Non-fungible tokens (NFTs) are becoming mainstream, and as new frontiers are explored (e.g., Videos, GameFi, Metaverse) it’s critical that digital assets are created in a way resilient to failures on any storage layer. In this post, we’ll make the case for storage layer maximalism (redundancy across many storage layers and protocols) and why every NFT needs a content-identifier (CID).
What exactly is an NFT?
If you’re familiar with how NFTs work, skip this section - this is just to get everyone up to speed.
Many people describe an NFT as a picture (or video or something) that “lives on the blockchain”. Because it “lives on the blockchain”, you get all these cool properties (Provenance! Automatic royalties! User ownership!) - which has birthed a whole movement in digital creation.
But dig in a bit, and you’ll quickly realize that there’s a bit more nuance in both how an NFT is structured and how your data is being stored. While the NFT (the actual token) lives on the blockchain - all the stuff (i.e., the information that shows up on NFT marketplaces, the image, other associated files - all commonly referred to as the metadata) associated with the NFT is usually referenced by external links[^1].

Above is the ERC-721 spec for NFTs. The TokenURI field contains a link to your metadata blob (seen below).

This (above) is your metadata blob. It contains a link to your image (highlighted).
While your NFT (the thing on the blockchain) may not disappear - we need to secure the NFT metadata as well[^2].
Challenges with Ensuring NFT Metadata Doesn’t Break
The web is a (surprisingly) fragile place:
- Links can point at dead content (404 errors)
- Domains can be sold, and the same link resolves to some unexpected new content at different points in time
- Malicious content can be placed at the other end of a link
- … the list goes on.
While this is an annoying problem when browsing the web, it becomes substantially more important when the link you’re relying on ties your million dollar (if not tens of millions) NFT to its associated JPEG. Especially for artists, marketplaces, and other developers enabling NFTs to be created - it's critical to ensure that these new digital creations are future-proofed.
You can split the risks NFT metadata face into two (related) challenges:
- Linking: How do we make sure the link our NFT uses directly points at the thing we want it to represent (i.e., my NFT is linked to its content, not someone else’s server)?
- Existence: How do we make sure the link our NFT uses always resolves the content we expect it to (i.e., prevent our jpegs from disappearing)?
Solving the linking problem
For the first challenge, we need to rethink how we use links. Traditionally, when we talk about links we’re talking about HTTP URLs - the type of URL that’s likely sitting in your browser as you read this.
HTTP URLs are location addressed - meaning the link itself is routing you to a specific location, and you’re trusting that:
- This is the location that you were expecting to go to
- The thing you find at that location is the thing you were looking for
A simple analogy might help make this clearer. Imagine we were talking about “To Kill A Mockingbird” and you were interested in getting a copy of it. In the way that HTTP URLs work, sharing this book with you would be like describing to you where you could find it (“Come to NYC, at these cross streets you’ll find a library, 3rd bookshelf in - two books from the right is the one you want). Naturally, many things can go wrong (you could get blocked from coming to NYC, the library could burn down, a different book could be in the same location you were told to go to, etc).
For NFTs, this is obviously not ideal - with HTTP links you’re relying on someone to make sure that (1) and (2) are true - and if that someone goes away you might be in trouble.
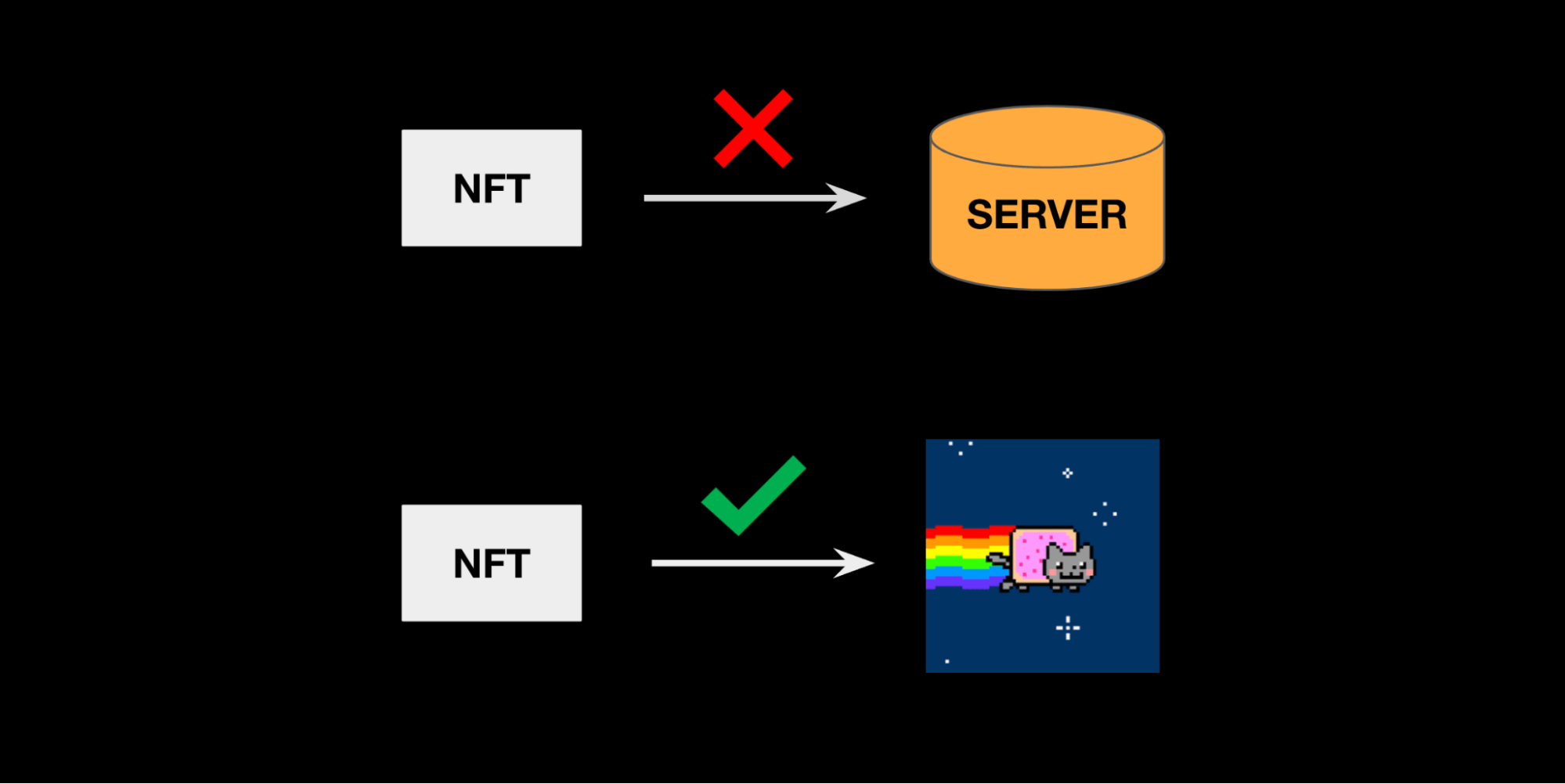
Your NFT should point at a thing, not point at a location.
Fortunately, this is where IPFS can help. IPFS is a suite of protocols allowing you to store and retrieve content based on a “fingerprint” (a cryptographic hash called a CID) of the content itself. The IPFS network is a peer-to-peer network - where anyone can ask for a CID and using some peer-to-peer magic the right content will find its way back to you as long as it's advertised on the network.
Revisiting our analogy: Imagine if instead of telling you where to go to find “To Kill A Mockingbird”, you were given a really specific description of what you were looking for (“Cover Art, Page Count, ISBN number, Author, etc). You could then ask me, your friends, your neighbors - anyone for a copy of the book, and whoever has the closest copy could give it to you (and you could verify you got the right thing back against the description). This is essentially what the IPFS protocol enables (with our very specific description being a CID).
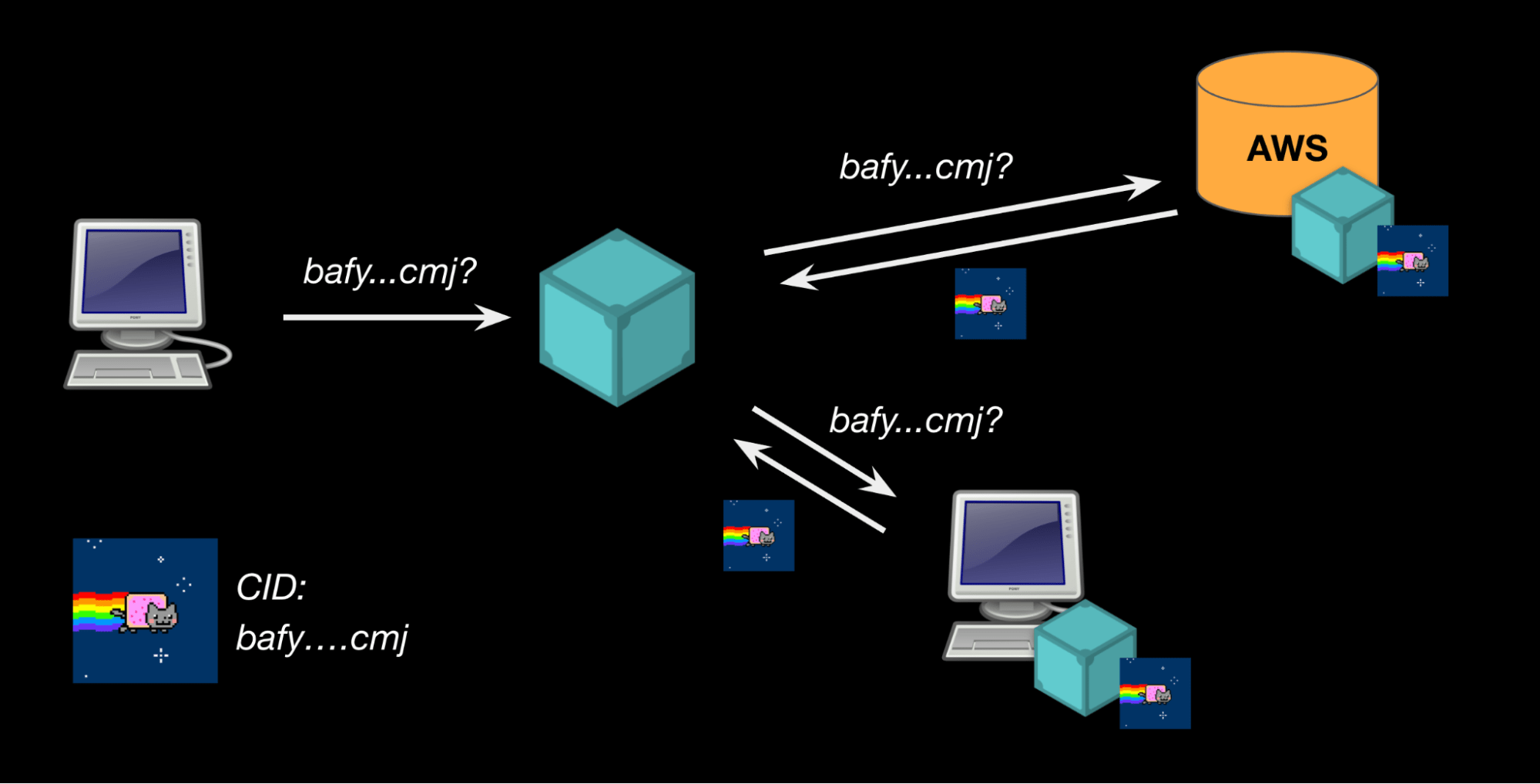
Example of a computer asking for the CID of Nyan Cat, and getting served Nyan Cat from multiple sources.
The magic of CIDs is that they’re a property of the data itself - (your JPEG can uniquely be referenced by its CID regardless of if it lives on my computer, your computer, Amazon’s computer, or a decentralized storage network). Critically, this means you can create immutable links to your content - with no assumptions about any other individual company, service, or protocol’s existence.
However, IPFS only solves the problem of making sure we can ask for (and verify the correctness of) our data irrespective of where that data lives. While this enables us to pursue many storage options in parallel, we need complementary solutions to ensure that someone has a copy of that data.
Solving the existence problem
There are a few approaches people typically take to ensuring persistence - depending on your belief in individual teams and projects, you may be more or less willing to use traditional infrastructure vs. decentralized storage. Specifically for NFTs, here are some of the more commonly used approaches:
- Pinning providers (e.g. Pinata, Infura): These are traditional businesses that run IPFS nodes as a service. Pinning providers offer custom features and tune performance to ensure high quality experiences.
- Filecoin: Offers hypercheap, deal-based, decentralized storage. Filecoin uses cryptographic proofs, incentives, and penalties across a decentralized network of storage providers to offer deterministic storage. A full chain of custody (from time of storage as well as “health checks” during the lifecycle of a deal) is recorded on-chain, with economic incentives to help subsidize cost, and economic penalties to ensure storage providers keep data online. Filecoin relies on higher order systems (e.g. smart contracts) to enable “permanent” deals. Today, Filecoin stores ~22,000 TiB of data.
- Arweave: Offers a pay-once-store-forever model for decentralized storage. The mechanism is backed by an endowment (with 1/6th the AR tokens) that receives payments from users. Ongoing emissions from the endowment are used to reward miners who win hashing competitions (where odds are improved by storing “rare” pieces of data on the network). While nodes can drop off the network with no penalty, the rational strategy for miners is to store as much data as they can. Today, Arweave stores ~34 TiB of data.
Various folks will make their case for their favored approach - but given the nacency of decentralized protocols it's critical to ensure that downstream assumptions (about another protocol’s economic model, resiliency) do not jeopardize the existence of an NFT. Most storage protocols are at best a few years old. When folks are committing millions (or tens of millions) of dollars it's necessary to plan for even the worst case scenarios - including the possibility that any individual protocol or service may fail or go offline.
Given the NFT itself can’t be mutated, its critical that how the data is stored is uncoupled from where its stored - if there’s even a fraction of a chance you believe one solution might fail, its worth considering using an IPFS URL + a CID as the canonical reference inside your NFTs metadata and then pursuing multiple storage paths in parallel.
Thankfully, regardless of your favored approach - it’s relatively straightforward to become a storage layer maximalist:
- Services like NFT.Storage and Estuary will push your content to IPFS and Filecoin
- Services like IPFS2Arweave and Arweave-IPFS can persist content on Arweave
- Services like Pinata and Infura will allow you to pin CIDs on hosted services
- You can even take matters into your own hands with the IPFS Desktop App
- … many more
With NFT.Storage, we aim to make adding resiliency to NFTs as simple as possible. For developers, you can easily use NFT.storage (for free!) during your minting process to pin your content in IPFS and push your content to Filecoin (with HTTP-free URLs). Use NFT.Storage as a primary service, or as a complement to your existing solutions - our goal is to ensure no NFTs ever go offline.
Stay tuned for some of our future plans - including how we’re going to save even the NFTs not stored via NFT.Storage!
[^1]: This varies a bit from chain to chain but an NFT is a token that meets some contract specs. You can take a look at the various standards and you’ll see one high-level thing in common: for all these chains, at some point, they link out to some external source to reference external content:
- Ethereum: ERC-721/1155 (tokenURI to Metadata.json on Ethereum, link to asset in Metadata.json)
- Solana: SPL
- Flow: Metadata standard
- Tezos: FA-2 By and large this is done because storing data on-chain is really expensive.
[^2]: It should be noted that there are some exceptions to this—like storing SVGs directly on chain—but this is a pretty small subset of what NFTs (hopefully) will end up enabling.