

New infrastructure, who dis? Elastic IPFS in production for NFT.Storage
Elastic IPFS in production for NFT.Storage today. See and feel the difference!
Since its inception in mid-2021, NFT.Storage has serviced over 70M uploads for off-chain NFT data. This has mostly provided a boon to the NFT ecosystem as a whole, with NFT.Storage’s mission to provide this storage as a public good, with the goal of demonstrating the potential of web3 by eventually decentralizing itself as a data DAO.
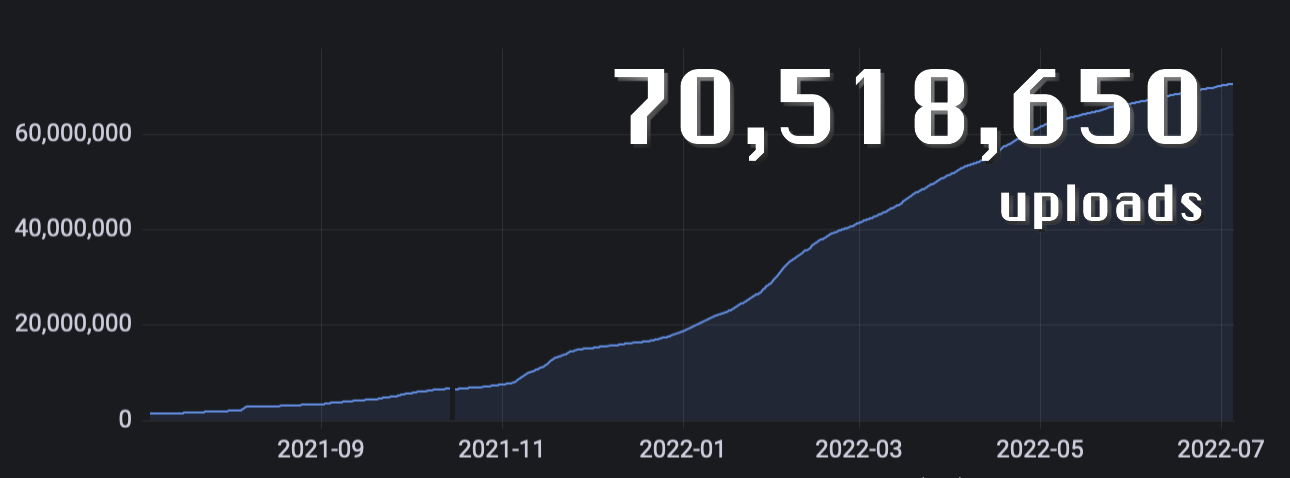
The NFT ecosystem has seen ebbs and flows in the last year plus, but NFT.Storage has seen steady growth in its usage.
Currently, NFT.Storage is run on the Web3.Storage platform, which involves the following steps:
- The user (usually) converts data into a DAG, generating the upload’s content ID (CID) locally (so the user can verify that the content is not tampered with). This is then packaged into a CAR file for uploading
- The upload gets sent to the NFT.Storage API
- The upload gets stored on NFT.Storage’s hosted IPFS infrastructure, making this data performantly available on the public IPFS network, including via IPFS gateways like nftstorage.link
- The upload is asynchronously put into a Filecoin storage deal, and stored with multiple independent Filecoin Storage Providers, with users able to cryptographically verify that the data is actually being stored by these Storage Providers (who are submitting validated proofs to the Filecoin blockchain)
As a result, NFT.Storage is a trustless service, which cryptography allows a user to verify the service’s work at every step, alongside other types of infrastructure (what we call “web2.5”).
Focusing on step 3 above, since launch, we have been managing and running our own, growing IPFS infrastructure, using go-ipfs nodes orchestrated by IPFS Cluster. Though this has been effective in getting NFT.Storage to where it is today, even early on we saw intermittent issues at our level of scale, with the infrastructure under stress during high load times (which would result in things like 5xx errors being returned to the user), and degraded performance as individual nodes got close to capacity.
Announcing Elastic IPFS

As a result, in parallel to our ipfs-cluster scaling, our team has been working hard on building a new open source IPFS implementation - one that is designed for our level of scale, architected in a cloud-native way - called Elastic IPFS. It is designed to be able to be run on most cloud infrastructure providers (we currently run in AWS), taking advantage of the scalability, efficiency, and cost of off-the-shelf infrastructure but centered around IPFS CIDs, meaning the data layer remains totally verifiable and decentralized.

Architecture diagram of the current Elastic IPFS implementation in AWS.
And at the end of June, after much testing, we rolled out this new infrastructure to the Web3.Storage platform (which includes NFT.Storage). We saw immediate improvements to NFT.Storage’s performance, and we’re ready to share this huge win for the entire NFT Ecosystem!
For NFT.Storage in particular, we saw a 99.9% decrease in 5xx errors to uploads, as well as huge drops in request time and perf variance across the board (mean from 3-8s to 2-3s, 99th% from 1-10 min to less than 10s).
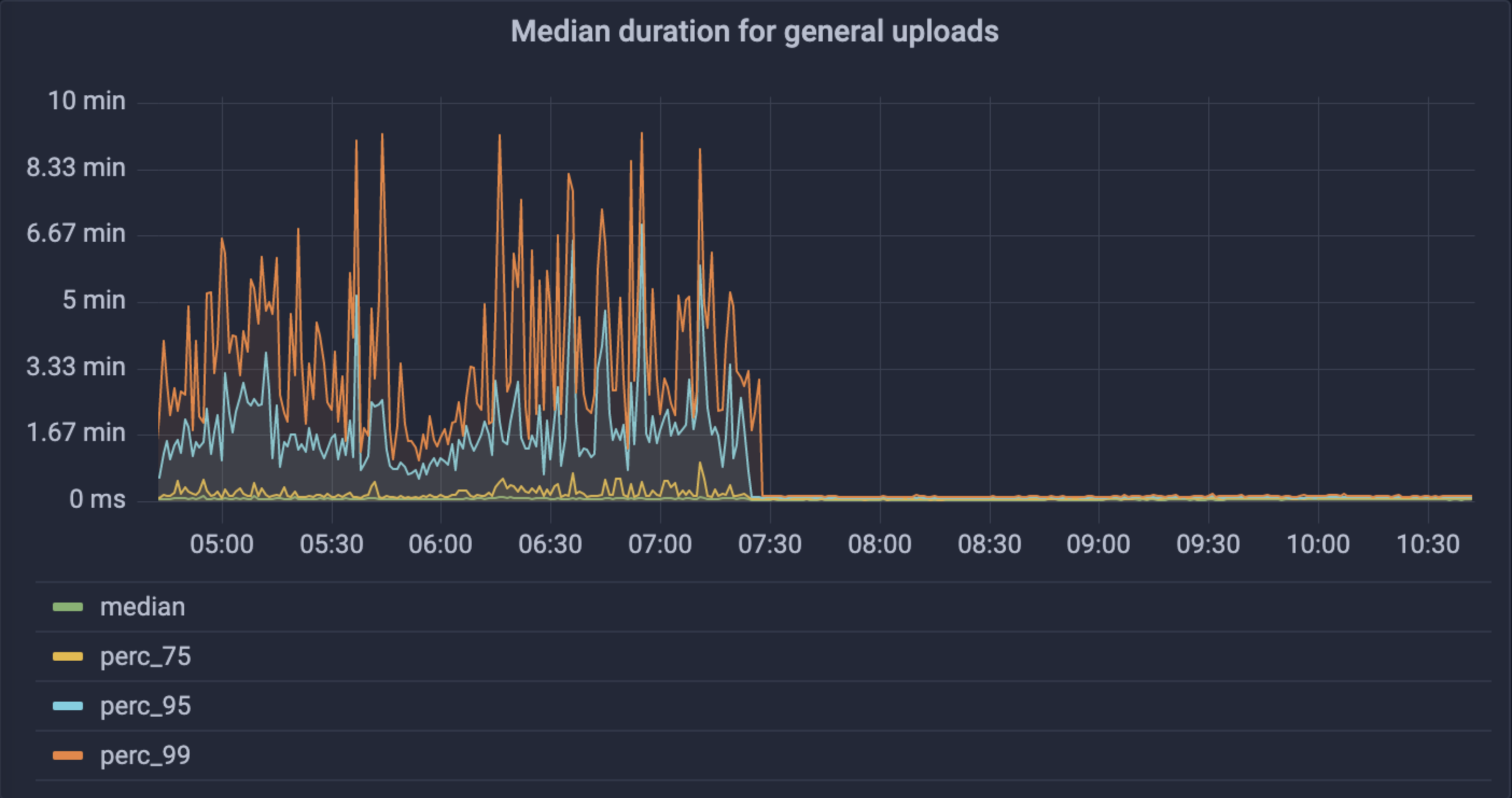
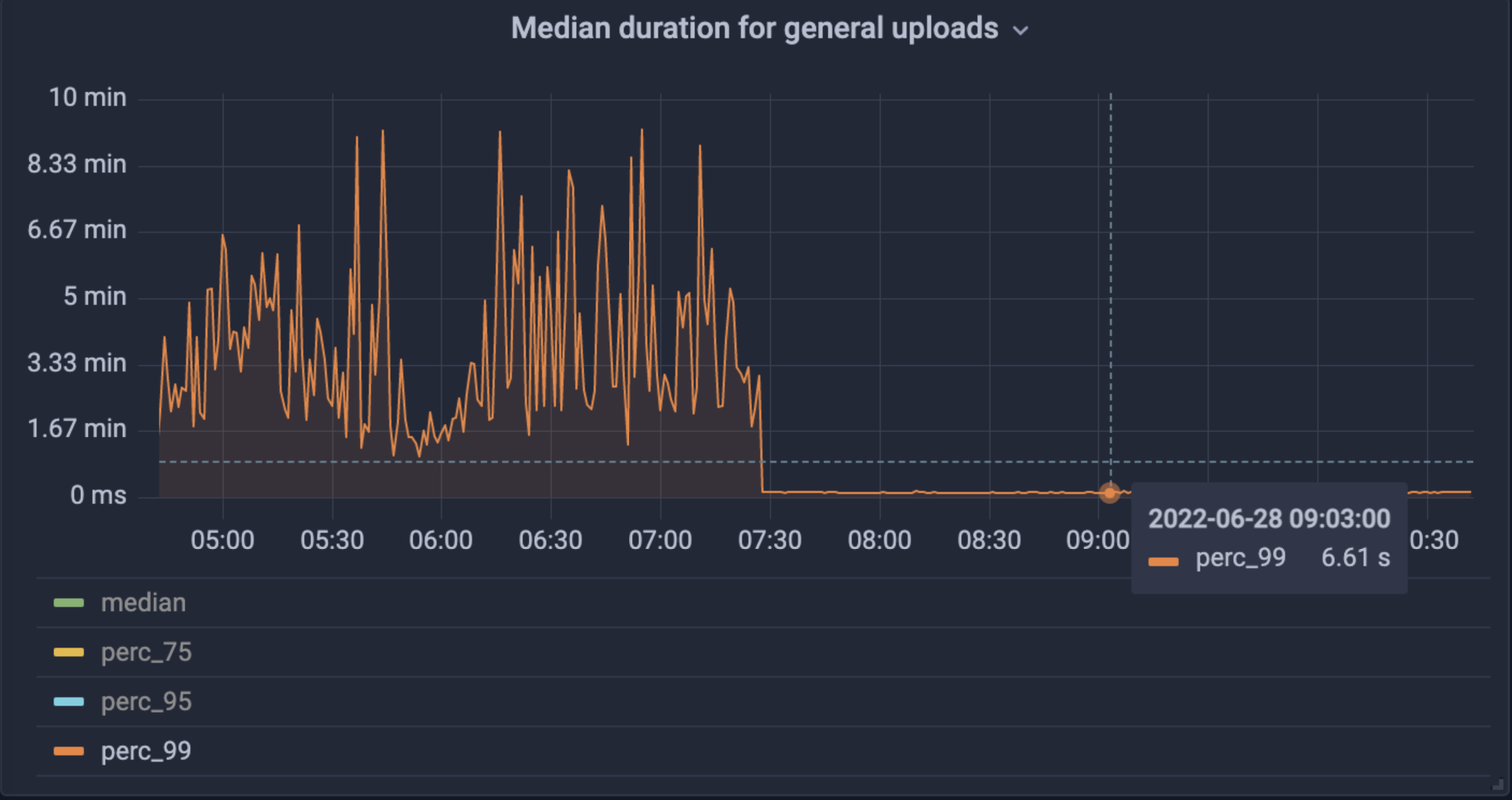
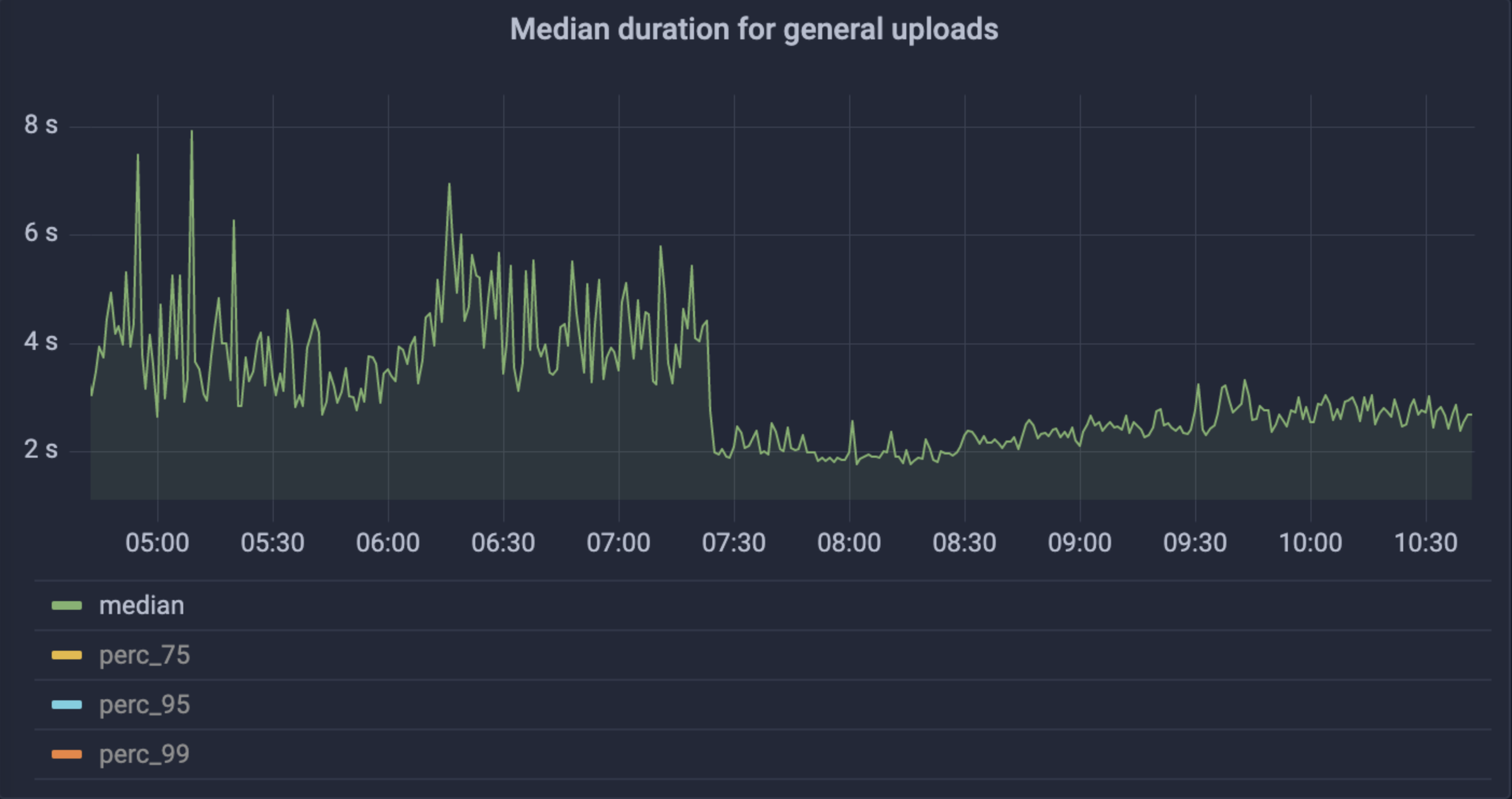
Immediately after rolling out Elastic IPFS, we saw huge drops in upload times and variance of upload time.
Further, we’ve had much more success broadcasting NFT.Storage content records to the public IPFS network’s distributed hash table (DHT). go-ipfs nodes under heavy load can have trouble broadcasting (and re-broadcast every 24h) to the DHT, which makes it hard for IPFS nodes not peered with NFT.Storage nodes to get the content performantly or at all.
What does this mean for NFT.Storage users? Uploads of all sizes being much faster and more reliable, more consistent availability and discoverability for your content, and the feeling that things just work.
Elastic IPFS under the hood
More literature on how Elastic IPFS works will be coming in the future. However, here are some notes on how it diverges significantly from the two major IPFS implementations today, go-ipfs and js-ipfs. And all the code is open source, so you can always dive into it yourself!
- No Blockstore: Blocks are retrieved directly from CAR files uploaded by users.
- Single peer ID: We run the service as a single peer ID across cloud service regions, leaning into off-the-shelf redundancy and load balancing from the cloud provider.
- Elastic Horizontal Scalability: New writes trigger serverless functions which index each CAR file into a DynamoDB table. Bitswap implementation is in Node.js managed by Kubernetes, and WebSocket load balancer distributes requests to individual BitSwap processes.
- No DHT re-providing: We leverage the Indexer Nodes to make provider records (i.e., records of who has the content) available to DHT queries via the hydra node bridge.
Moving the needle
Building, deploying at scale, and releasing a brand new implementation of IPFS in less than a year has been a herculean effort. Thanks to everyone involved - the NFT.Storage and Web3.Storage team, NearForm (who we partnered with to build Elastic IPFS), the Indexer team at Protocol Labs, and many more! And here’s to the next 70 million uploads!